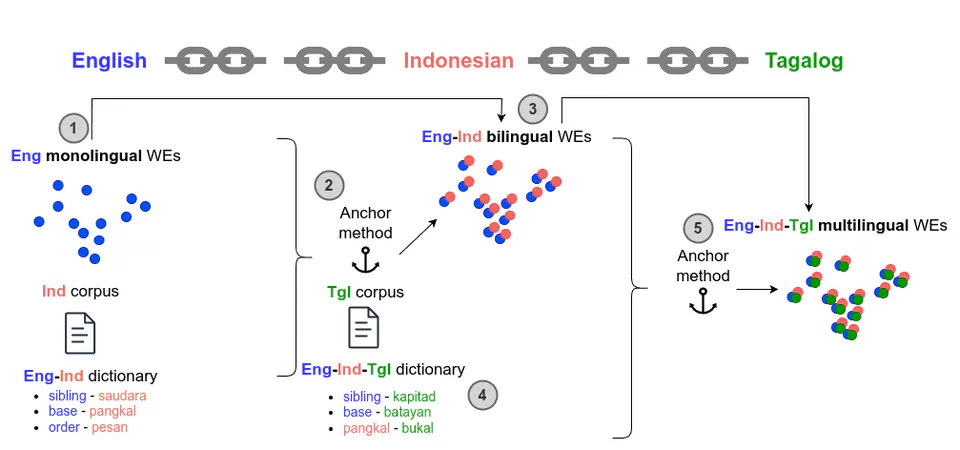
Anchor-based cross-lingual word embeddings for very low-resource languages.
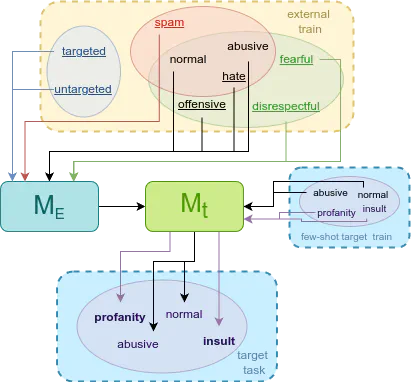
Hate speech and offensive language detection by combining multiple datasets with different label set.
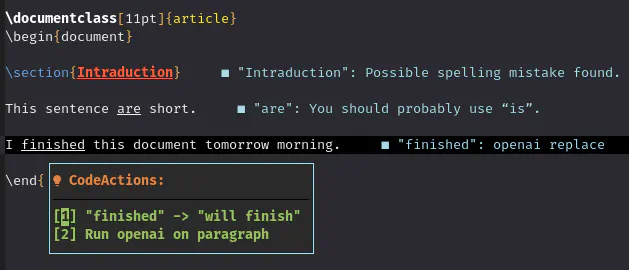
Integrate spell checking and grammar correction with LLMs to IDEs.
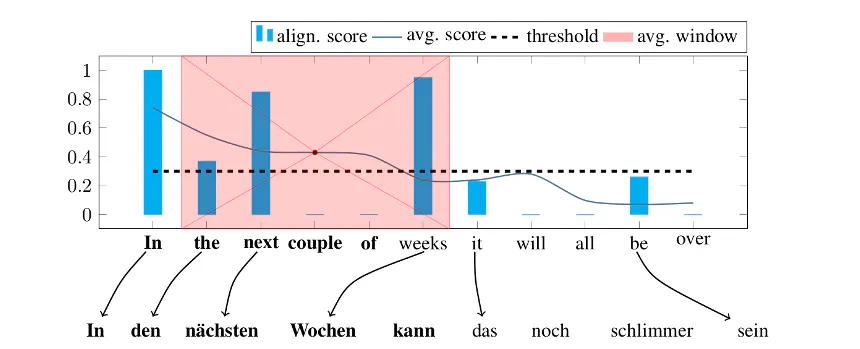
Unsupervised parallel sentence extraction from comparable corpora.